저번 생성모델(Generative model)에 이어서, 이번에는 감히 간단하게 강화학습(Reinforcement Learning)과 관련한 글을 정리해보려고 한다. 이 글은 개념만 잡는 글로 혹시라도 기초를 아는 분들은 이 글을 패스해도 무관할 것 같다. 개인적으로 필자가 최근에 가장 관심을 많이 기울이는 분야라서 조금 내용이 길어질수도 있다. 또한 여기서 세부적으로 나오는 알고리즘은 추후 PyTorch로 직접 구현도 해볼 예정이다.
이 글은 고려대학교 감태의 교수님의 딥러닝 강의 중 생성모델과 관련된 내용을 정리하여 재구성하였다. 교수님의 설명과 함께 필자의 주관적인 내용도 들어갔을 수 있는 점 참고하길 바란다. 추가적으로 내용상 오류가 있거나 부족한 부분이 있다면 언제든지 댓글로 피드백 바란다.
생성모델(Generative model)이란 무엇일까?
내일이 기말고사라서 간단하게 강의 정리도 해야해서, 오늘은 비지도학습(Unsupervised learning) 중에서 클러스터링(Clustering)과 함께 가장 대표적인 예시 중 하나인 생성모델(Generative model)에 관련해
minsuksung-ai.tistory.com
들어가기 앞서
앞서 계속 설명했지만, 우리가 아는 머신러닝은 여러가지 학습기법으로 분류될 수 있다. 그 중에서도 오늘날의 딥러닝의 대중성과 인공지능의 성장에 가장 많이 기여했다고 볼 수 있는 강화학습(Reinforcement Learning)을 소개하겠다. 추후 알파고(AlphaGo)에 대해서도 간단하게 설명하겠지만, 지금의 알파고를 있게 만든 일등공신이다.
강화학습이란 무엇일까?

예를 들면, 어린아이가 자전거를 배우는 상황을 가정해보자. 사실 자전거를 배우는 법(?)이라고 하면 뾰족하게 말할 수 있는 방법이 있을까? 자전거를 배우는 법은 직접 타보고 경험하면서 안 넘어지게끔 연습하는 방법 밖에 없다. 자전거를 배우는 것은 수학이나 과학 문제 풀듯이, 라벨(Label)이 정해진 것이 아니다. 오른쪽으로 넘어질 것 같다면, 왼쪽으로 핸들을 15도 틀고, 오른쪽으로 넘어질 것 같다면 왼쪽으로 핸들을 25도 트는 것과 같이 아니라는 말이다. 어떻게 해서든 최대한 넘어지지 않도록 행동하는게 자전거를 잘 타는 것이므로(사실 어떻게 정의하느냐에 따라 다르긴 하겠지만) 어린아이는 넘어지지 않도록 학습할 것이다. 이렇게 학습하는 방법이 강화학습이라고 말할 수 있다.
강화학습에 필요한 요소들
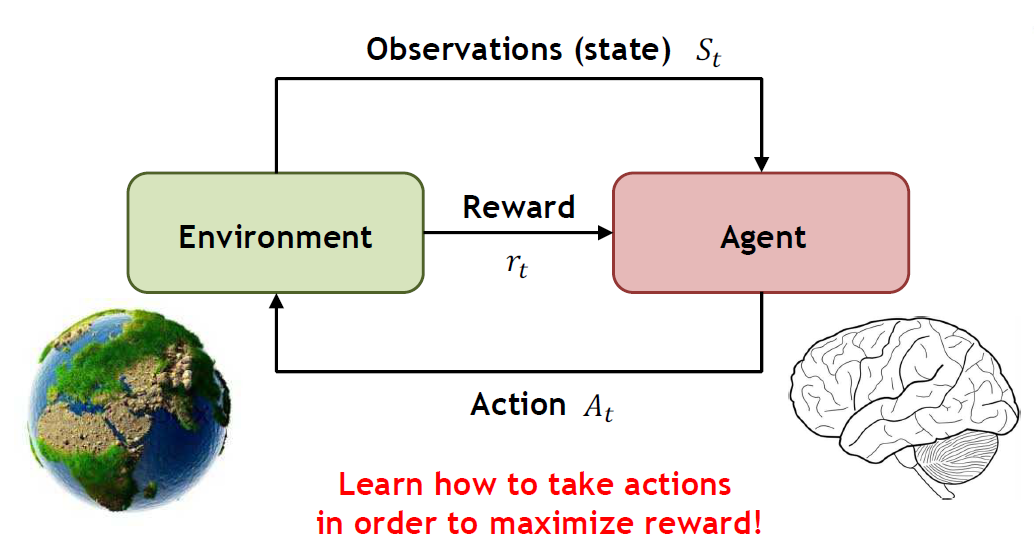
본격적으로 그럼 이런 강화학습을 하기 위해선 무엇이 필요할까? 강화학습을 간단하게 한마디로 요약하자면, 아래와 같이 한줄로 요약할 수 있다.
주어진 Enviroment에서 Agent가 더 높은 Reward를 위해 최적의 Action을 취해나가는 학습 과정
다시 자전거를 배우는 어린아이로 예시를 들자면, 어린아이(Agent)는 학교 운동장(Enviroment)에서 넘어지지 않기 위해서 핸들을 이리 저리 흔들면서(Action) 노력한 결과, 넘어지지 않고 지속된 시간(Reward)이 길어졌다! 사실 매우 간단하게 설명했지만, 필자가 적은 것처럼 Enviroment나 Reward나 Action이 저렇게 고정될 필요는 없다. 다만 여기서 기억해야할 것은 강화학습을 하기 위해선 저렇게 4가지는 필수라는 점이다.
MP, MRP, and MDP
강화학습을 알기 앞서, 우리는 MP, MRP, 그리고 MDP가 각각 무엇인지 알아야할 필요가 있다.
Markov Process (MP)
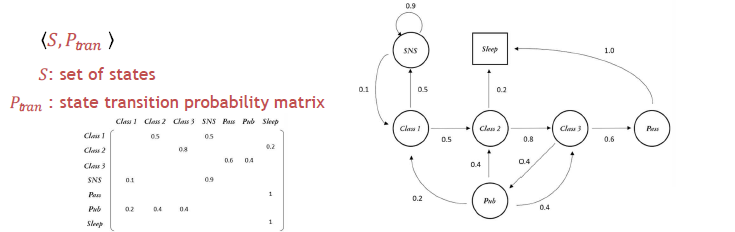
MP는 미래에 가능한 이벤트들의 순서를 표현하기 위한 모델이다. 즉 앞으로 발생할 수 있는 이벤트들에 대한 순서를 확률로 모델링하겠다는 것이다. 이러한 MP는 현재 발생한 이벤트는 이전의 이벤트에만 영향을 받는 가정인 Markov Property를 기반으로 한다. 예를 들어, 오늘 날씨가 맑은 건 아무래도 어제 날씨가 맑았기 때문이지, 1달전에 날씨가 영향을 미쳤을리 없는 것과 비슷하다. 이러한 성질을 Memoryless property라고도 한다. 아래의 예시처럼 MP는 State와 State간 Transition Probability로 나타낼 수 있는데, 결국 이는 Matrix 형태로 나타낼 수 있다.
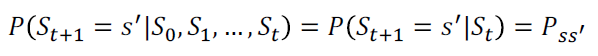
Markov Reward Process (MRP)
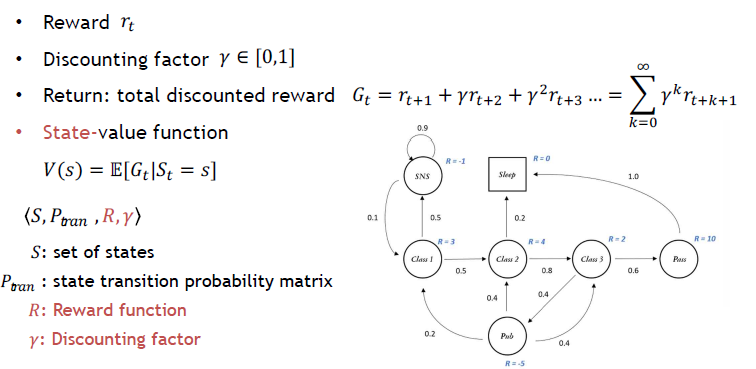
MRP = MP + Reward
MRP는 사실상 MP에서 각 State마다 좋고 나쁨을 나타낼 수 있는 Reward가 추가된 개념이다. 이러한 Reward가 계속 쌓일텐데, 앞으로 받을 모든 Reward를 계산한게 Return이 된다. 여기서 미래의 받을 보상과 지금 받을 보상의 가치를 다르게 평가하기 위해서 Discounting factor라는 개념이 필요하다. 마치 당신에게 지금 10000원 받을지 혹은 미래에 10000원을 받을지 물어본다면 당연히 지금 10000원을 선택하듯이, 지금의 Reward와 미래의 Reward는 다르기 때문이다. 이렇게 현재 State에서 Return의 기댓값을 정의한게 바로 State-value function이라고 한다.
Markov Decision Process (MDP)
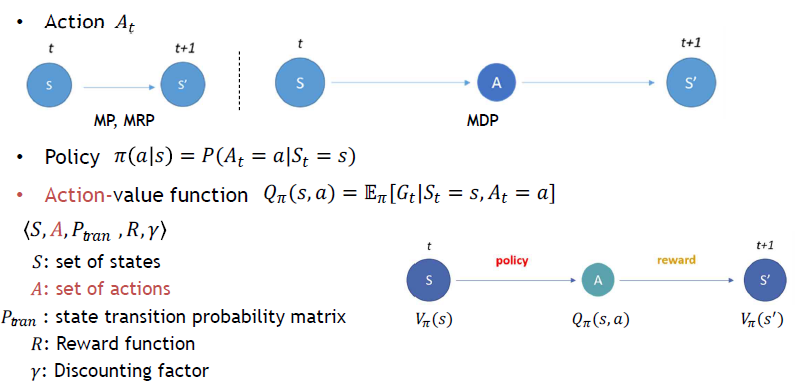
MDP = MRP + Decision = MP + Reward + Decision
MDP는 MRP에서 Decision(Action)이 추가된 개념이라고 보면 된다. 강화학습에서는 이 MDP를 통해서 모델링을 한다고 보면 된다. MP와 MRP에서는 현재 State에서 다음 State로 바로 이어졌지만, MDP에서는 다음 State로 넘어갈 때, 어떤 Action을 수행하느냐에 따라서 바뀐다. 즉 어떤 Action을 하느냐는 확률에 따라서 결정된다. 그리고 현재 State에서 할 수 있는 다양한 Action들이 있고, 그에 따라서 여러가지 다음 State가 존재할 수 있다. 현재 State에서 어떤 Action을 수행할 것인지를 Policy라고 한다. 앞선 State-value function은 현재 State에 따라서 받을 수 있는 Return의 기댓값이었다면, 여기서는 Action-value function은 현재 State에서 특정 Action에 따라서 받을 수 있는 Return의 기댓값이라고 할 수 있다. 여기서의 핵심은 바로 이 Action이다.
Model-Based vs Model-Free
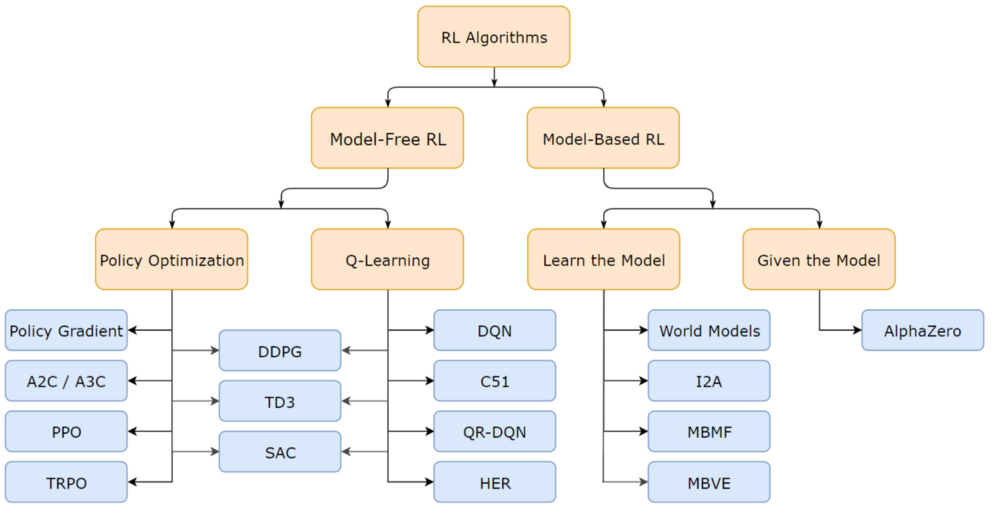
강화학습을 공부하면서 항상 궁금했다. 강화학습 모델들을 구분 짓는 기준이 너무 많았기 때문에 도대체 뭘 기준으로 정리해야할까? 어떤 곳에선 Value/Action 기준으로 나누기도 하고, 어떤 곳에선 Model-Based와 Model-Free로 나누기도 하니까 도대체 정리가 안됐다. 일단 결론부터 말해주자면 항상 State 기준으로 생각하면 된다. 즉 기준을 State로 봤을 때 Reward로 계산하면 State-value라고 하고, 기준을 State에서의 각 Action을 Reward로 계산하면 Action-value라고 말할 수 있다.
State-Value Function
어떤 State 에서 특정 Policy 를 따라서 Action을 계속 취했을 때 얻게 되는 Reward들의 기대값을 State-value 라고 부른다. 이는 해당 State에 있게 되면 앞으로 얼마나 큰 Return을 얻을 것을 기대할 수 있는가를 의미할 수 있다.
Value Iteration
Value iteration 은 State-value가 최적이 되도록 하는 알고리즘이다. 이 때 정책은 최적의 정책처럼 State-value값이 최대가 되는 방향으로 Action을 취한다고 가정하고 그 때의 State-value값을 구한다. Value iteration처럼 각 State에서 State transition probability와 그에 따른 Reward를 알아야하는 모델의 경우를 Model-based 모델이라고 한다.
Action-Value Function
어떤 State 에서 어떤 Action 를 취한 후에 특정 Policy 를 따라서 Action을 계속 취했을 때 얻게 되는 Reward들의 기대값을 Action-value 라고 부른다. 이는 해당 State에서 어떤 Action을 취하게 되면 앞으로 얼마나 큰 Return을 얻는 것을 기대할 수 있는가를 의미한다.
Q-Learning

Q-learning 은 Action-value가 최적이 되도록 하는 알고리즘이다. 이 때 정책은 최적의 정책처럼 Action-value가 최대가 되는 방향으로 Action을 취한다고 가정하고 그 때의 Action-value를 구한다. Q-learning처럼 각 State에 State transition probability와 그에 따른 Reward를 알 필요가 없는 모델을 Model-free 모델이라고 한다. 사실상 많은 강화학습 책에 나온 알고리즘들은 대부분 Model-free 모델을 기반으로 한다.
글을 마무리하며

최근에 읽었던 블로그 중에서 가장 정리를 깔끔하게 했다고 생각되는 포스팅은 오태호님의 블로그글이다. 강화학습이 이제 무엇인지 대략 알았지만, 정말 구체적으로 어떻게 동작하는지 궁금하다면 꼭 필독해보자. 사실 여기서 소개한 Q-Learning 말고도 DQN(Deep Q-Network), SARSA, Policy Gradient, REINFORCE, Actor Critic, TD3, SAC, A2C, DDPG(Deep Deterministic Policy Gradient), A3C, PPO(Proximal Policy Optimization), TRPO(Trust Region Policy Optimization) 등 너무나 많은 알고리즘이 존재한다. 필자도 블로그를 통해 앞서 말한 유명한 알고리즘을 정리할 계획이다.
참고자료
https://spinningup.openai.com/en/latest/
Welcome to Spinning Up in Deep RL! — Spinning Up documentation
© Copyright 2018, OpenAI. Revision 038665d6.
spinningup.openai.com
https://dnddnjs.gitbooks.io/rl/content/
Preface · Fundamental of Reinforcement Learning
No results matching ""
dnddnjs.gitbooks.io
https://brunch.co.kr/@chris-song/102
최신 강화학습 알고리즘 요약
공식 없이 훑어 보는 최신 강화학습 트렌드 | 일하다가 덕질하려고 잠시 강화학습 글 번역했습니다. https://towardsdatascience.com/getting-just-the-gist-of-deep-rl-algorithms-dbffbfdf0dec RL (Reinforcement Learning) 연�
brunch.co.kr
https://teamdable.github.io/techblog/Reinforcement-Learning
Reinforcement Learning
안녕하세요. 오태호입니다.
teamdable.github.io
https://medium.com/@SmartLabAI/reinforcement-learning-algorithms-an-intuitive-overview-904e2dff5bbc
Reinforcement Learning algorithms — an intuitive overview
Author: Robert Moni
medium.com
Machine learning 스터디 (20) Reinforcement Learning - README
들어가며 첫 글에서 Machine Learning은 크게 세 가지로 구분된다는 얘기를 했었지만, 지금까지 다뤘던 주제들은 모두 supervised learning이거나 unsupervised learning이었다. Reinforcement learning은 그 둘과는 구�
sanghyukchun.github.io
https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf
https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PLzuuYNsE1EZAXYR4FJ75jcJseBmo4KQ9-
https://www.nature.com/articles/nature14236
https://www.youtube.com/watch?v=dZ4vw6v3LcA&list=PLlMkM4tgfjnKsCWav-Z2F-MMFRx-2gMGG&index=1
'강화학습(Reinforcement Learning)' 카테고리의 다른 글
| [리뷰] 심층 강화학습 인 액션 (1) | 2020.11.23 |
|---|---|
| [영상리뷰] 강화학습을 이용한 주문집행전략 (AI Order Execution Optimization) (0) | 2020.06.09 |