내일이 기말고사라서 간단하게 강의 정리도 해야해서, 오늘은 비지도학습(Unsupervised learning) 중에서 클러스터링(Clustering)과 함께 가장 대표적인 예시 중 하나인 생성모델(Generative model)에 관련해서 글을 정리해보았다.
이 글은 고려대학교 감태의 교수님의 딥러닝 강의 중 생성모델과 관련된 내용을 정리하여 재구성하였다. 교수님의 설명과 함께 필자의 주관적인 내용도 들어갔을 수 있는 점 참고하길 바란다. 추가적으로 내용상 오류가 있거나 부족한 부분이 있다면 언제든지 댓글로 피드백 바란다.
머신러닝에서의 3가지 학습기법들
머신러닝에서는 크게 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 그리고 강화학습(Reinforcement Learning), 이렇게 3가지로 정리할 수 있다. 이러한 기준은 물론 상호베타적이진 않지만, 보편적으로 이렇게 나누고 있다. 어쨌든, 오늘은 그 중에서도 비지도학습과 관련하여 알아보려고 한다.

지도학습(Supervised Learning) vs 비지도학습(Unsupervised Learning)
이 두가지 학습 기법은 아래와 같은 표로 요약하여 비교 설명할 수 있다.
| 지도학습(Supervised Learning) | 비지도학습(Unsupervised Learning) | |
| 목표(Goal) | 매핑할 함수를 학습 (Learn a function to map) |
주어진 데이터 속 숨겨진 패턴을 학습 (Learn some underlying hidden structure of the data) |
| 레이블링 유무(Label) | 레이블 존재(O) | 레이블 존재(X) |
| 활용(Application) | 이미지 분류(Image classification) 객체 인식(Object detection) 이미지 분할(Semantic segmentation) 이미지 캡셔닝(Image captioning) |
클러스터링(Clustering) 차원 축소(Dimensionality reduction) 특성 학습(Feature learning) 밀도 추정(Density estimation) |
생성모델(Generative model)이란 무엇일까?
생성모델은 주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델이다. 이와 같이 학습 데이터와 유사한 샘플을 뽑아야하기 때문에, 생성 모델에는 학습 데이터의 분포를 어느 정도 안 상태에서 생성하거나(Explicit) 잘 모르지만 그럼에도 생성(Implicit)하는 다양한 모델들이 존재한다. 조금 감이 오질 않는다면, 아래와 같은 예시를 들 수 있다. 아래와 같이 학습 데이터 속에는 각 샘플들마다 픽셀들의 분포를 알 수 있다. 이러한 분포들만 제대로 알아낼 수 있다면 오른쪽 그림처럼 완전히 동일하진 않지만, 어느 정도 학습 데이터와 유사한 데이터를 생성할 수 있다. 장황하게 설명했지만, 결국 생성모델에서 가장 중요한 것은 학습 데이터의 분포를 학습하는 것이 제일 중요하다고 말할 수 있다. 학습 데이터의 분포와의 차이가 적을수록 실제 데이터와 비슷한 데이터를 생성할 수 있을 것이다.

이러한 생성모델에는 여러가지 방식들이 있는데, 이 중에서 몇가지만 설명하자면, 학습 데이터의 분포를 기반으로 할 것인지(Explicit density) 혹은 그러한 분포를 몰라도 생성할 것인지(Implicit density)로 나뉘게 된다. 이러한 학습 데이터의 분포를 직접적으로 구하는 방법(Tractable density)이 있고, 이러한 분포를 단순히 추정하는 방법(Approximate density)이 있다. 여기에 추가적으로 생성모델 중에서도 가장 인기를 끌고 있는 적대적 생성모델(Generative Adversarial Network, GAN)도 있습니다.

1. Explicit density
1.1. Tractable density

여기서는 직접적으로 학습 데이터의 분포를 학습하기 위해서, PixelRNN/CNN은 연쇄법칙(Chain rule)을 통해서 직접 구할 수 있다. 조금 더 설명하자면, 이전 픽셀들의 값을 통해서 현재 픽셀의 값을 결정하겠다는 것이다. 이렇게 하면 이미지 전체에 대해서 데이터를 생성할 수 있을 것이다. 여기서의 목표는 아래 함수를 최대화하는게 목표가 될 것이다.

1.1.1. PixelRNN
Pixel RNN은 이전 픽셀을 어떻게 정의할 것인가라는 문제가 가장 중요하다. Pixel RNN은 왼쪽 상단의 픽셀부터 오른쪽 하단의 픽셀 방향으로 순서를 잡았다. 이렇게 하면 이전 픽셀이 어떤 것인지 정의할 수 있게 된다. 이미지에서 이렇게 순서를 정해준다면 RNN/LSTM과 같은 모델을 적용하여 인코딩해서 데이터를 생성할 수 있게 될 것이다.
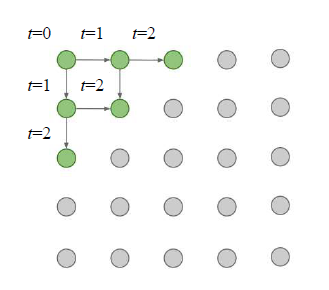
1.1.2. PixelCNN
Pixel CNN은 반대로 RNN이 아니라, CNN 모델을 학습하는 것이다. 기존의 CNN과 다른 점은 필터의 가중치를 전부 사용하지 않고, 현재까지 알게 된 정보만을 기준으로(아직 거치지 않은 픽셀은 0으로 처리) 필터를 구성하게 된다.

Pixel RNN과 CNN에서의 장단점을 정리해보자. 일단 장점은 학습 데이터의 이미지 확률 분포 자체를 학습할 수 있고, 확률 자체가 명확하기 때문에 생성된 이미지도 뚜렷하다는 점이다. 단점으로는 순서 자체를 학습했기 때문에 속도 측면에서 느리다는 점이다.
1.2. Approximate density

딥러닝을 공부하는 사람들 중에서도 GAN에 관심 많은 사람들이라면 한번쯤 오토인코더(Auto Encoder, AE)를 들어봤을 것이다. 이번에는 AE와 더불어 AE에서 확장되어 지금까지도 많이 사용되고 있는 Variational Auto Encoder와 마지막으로 Restricted Boltzmann Machine에 대해서도 간단히 알아보자.
1.2.1. Auto Encoder (AE)

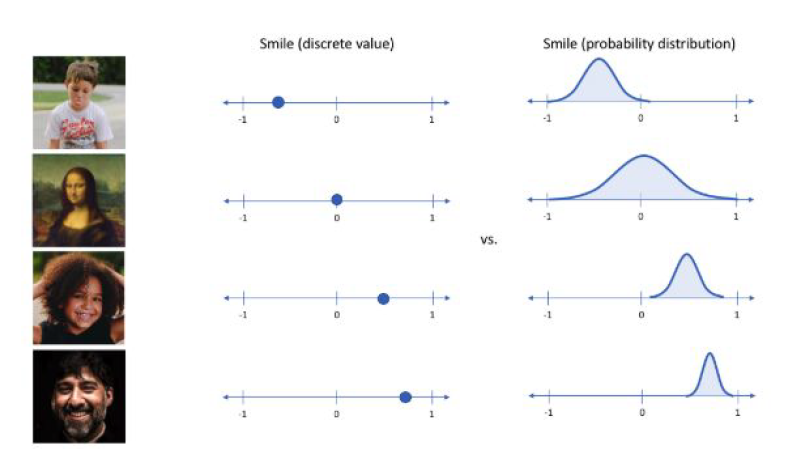
오토인코더는 위 그림과 같이 입력을 기반으로 특징을 추출하고 추출된 특징으로 다시 원본 데이터를 출력하는 네트워크이다. 오토인코더는 크게 2가지 파트로 구성이 되어 있는데 하나는 인코더(Encoder)이고 다른 하나는 디코더(Decoder)이다. 얼핏 보면 간단한 신경망이지만 네트워크에 여러가지 방법으로 제약을 줌으로써 복잡한 구조를 만들 수 있다. 결국 정리하면 오토인코더는 라벨링되지 않은 데이터로부터 저차원의 특징(Low-dimensional feature representation)을 학습한 비지도학습라고 말할 수 있다. 여기서 인코더에 추출된 특징을 잠재 코드(Latent code)라고 한다. 예를 들면 웃는 남자의 사진에서 6개의 특징을 추출한다고 할 때, 추출된 특징들을 하나의 특정 숫자값으로 갖을 수 있다.

1.2.2. Variational Auto Encoder (VAE)
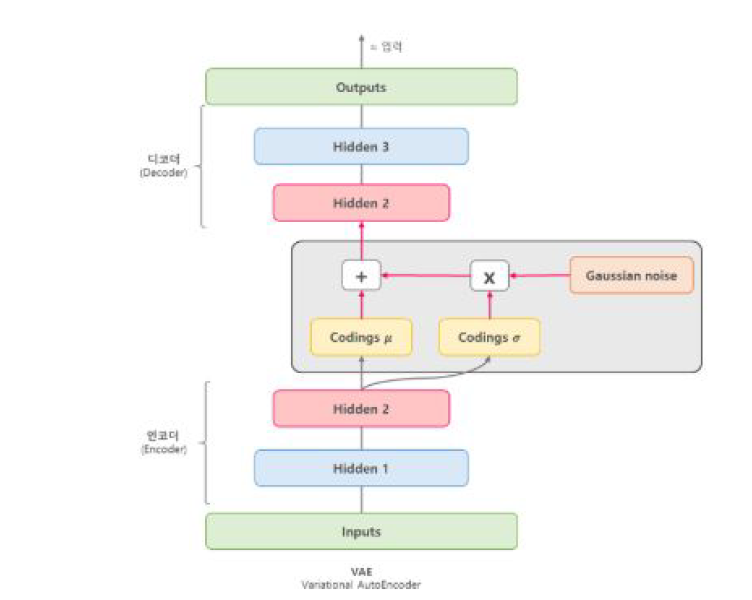
VAE는 단순히 입력값을 재구성하는 AE에서 추출된 잠재 코드의 값을 하나의 숫자로 나타내는 것이 아니라, 가우시안 확률 분포에 기반한 확률값으로 나타낸다. 다시 말해서, 이 둘의 가장 큰 차이점은 바로 AE의 잠재 코드값이 어떤 하나의 값이라면, VAE에서의 잠재 코드값은 평균과 분산으로 표현되는 어떤 가우시안 분포이라고 할 수 있다. 아래 그림은 잠재 코드를 표현할 때, AE와 VAE의 차이점을 도식화한 그림이다.
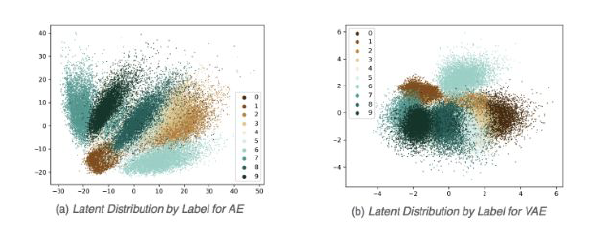
아래 그림은 MNIST 데이터에 대해서 잠재 공간(Latent space)을 표현한 그림인데, 각 점의 색깔은 MNIST 데이터와 같이 0~9 숫자로 표현되어 있다. 좌측은 AE가 만들어낸 잠재 공간이고, 우측은 VAE가 만들어낸 잠재 공간이다. AE가 만들어낸 잠재 공간은 군집이 넓게 퍼져있고, 중심으로 잘 뭉치지 않고 퍼져있는데 반해서, VAE가 만들어낸 잠재 공간은 중심으로 좀더 컴팩트하게 잘 뭉쳐있는 것을 확인할 수 있다. 따라서 원본 데이터를 재생하는데, AE에 비해서 VAE가 유리하고, 잠재공간을 통해서 데이터의 군집을 파악하는데 군집이 잘 형성되어 있기 때문에 VAE를 통해서 데이터의 특징을 파악하는데 좀더 유리하다.
정리하면, VAE는 Intractable density를 구할 수 있으며, 여러가지 수식 전개를 통해서 Lower bound 값을 구할 수 있다. VAE의 장점 중 하나는 확률 모델을 기반으로 했기 때문에, 조금 더 유연하게 계산할 수 있다. 또한 네트워크 나온 특징맵(Feature map)을 가지고 다른 일을 수행할 수 있다. 하지만 VAE의 단점이라면 density를 직접적으로 구한게 아니기 때문에, PixelRNN이나 PixelCNN과 같이 직접적으로 density를 구하는 모델보다는 성능이 떨어진다는 단점이 있다.


1.2.3. Restricted Boltzmann Machine (RBM)
지금까지 봤던 구조와 달리, 조금 특이한 구조를 소개하겠다. 바로 제한된 볼츠만 머신(RBM)이다. RBM은 입력노드와 출력노드가 따로 정해져 있지 않는 구조이다. 즉 방향성이 없는 모델이기 때문에 입력이 출력으로 되고, 출력이 다시 입력으로 될 수 있다. RBM을 조금 더 풀면 아래와 같은 구조로 펼칠 수 있다.


학습시키는 과정이 다소 복잡하다. 왜냐하면 이 모델은 방향성이 없기 때문에, 하나를 고정시키고 다음, 그리고 학습을 진행하고, 다시 고정시키고 학습을 진행하는 방식을 반복한다. 이와 관련해서 궁금하다면 깁스 샘플링(Gibbs sampling)을 더 알아보도록 한다. 그리고 이러한 RBM을 여러 층으로 쌓은게 결국 Deep Belief Network(DBN)이라고 할 수 있다.

2. Implicit density
여기까지 오는데 다소 힘들었을 것이다. 사실 필자도 다 알고 정리하는 것은 아니라 설명이 미흡한 점은 양해바란다. 하지만 이제 하이라이트가 남았다. 바로 적대적 생성모델이다.

GAN(Generative Adversarial Networks)
적대적 생성모델(Generative Adversarial Networks), 즉 GAN을 설명하는데 게임이론과 같은 접근 방식이 가장 편한데, 가장 많이 드는 예시가 바로 위조지폐범과 경찰이다. 위조 지폐를 만드는 사람(Generator)은 더욱 더 진짜같은 위조 지폐를 만들기 위해서 노력할 것이고, 경찰(Discriminator)는 위조 지폐인지 진짜 지폐인지 잘 구분하려고 노력할 것이다. 마치 모든지 뚫을 수 있는 창과 어떠한 것이든 막을 수 있는 방패의 대결같다. 한쪽이 잘하면 다른 한쪽도 잘하려고 노력할 것이기 때문에 결국에는 위조 지폐가 진짜 지폐와 거의 차이가 없을 정도로 될 것이다. 이러한 컨셉이 바로 GAN이라고 생각하면 된다. 이러한 아이디어는 Ian Goodfellow가 무려 6년전, 2014년 NIPS에서 발표한 논문이다. (본인 동료와 술 마시면서 생각해낸 아이디어를 집에 와서 하룻밤만에 뚝딱 완성시켰다고 하는데, 과연 천재같다.)

말로 이렇게 장황하게 써놓으면 감이 안 올 수 있는데, 수식으로 설명하면 아래와 같이 깔끔하게 정리할 수 있다. Discriminator는 어떻게 해서든 objective function을 최대화하는 방향으로 학습할 것이고, Generator는 objective function을 어떻게 해서든 최소화하는 방향으로 학습시킬 것이다. 이를 Minmax Game이라고도 한다.

물론 저 식대로 하면 초반에 Gradient가 잘 학습되지 않는 문제가 발생하여 일부 식을 수정해서 학습하긴 하는데, 더 구체적으로 이와 관련해서 알고 싶다면 여기로 가서 확인하길 바란다. 필자보다 더욱 쉽고 간결하게 정리해두었다.



DGGAN
앞서 GAN은 MNIST와 같은 간단한 이미지는 잘 생성하긴 하는데, 개나 고양이와 같이 복잡한 이미지를 생성하는데 한계점이 있었다. Deep Convoluntional GAN(DCGAN)은 GAN의 Generator 부분을 구성할 때, 이미지에 특화된 모델인 CNN을 적용한 모델이라고 생각하면 된다.

아래와 같이 DCGAN은 GAN과 달리, 사람도 구별하기 어려울 정도로 정교한 이미지를 생성할 수 있다. 기존 GAN은 생성된 이미지가 진짜인지 가짜인지 확연하게 구별할 수 있었는데, DCGAN을 보면 이제 사람도 구별하기 어려운 이미지를 생성하는 것을 확인할 수 있다. 그리고 이제 Latent space를 잘 변화시키면 이미지도 다르게 생성될 수 있음을 알 수 있다. 이러한 사실을 응용하면 아래와 같이 연산을 할 수 있게 된다.



CycleGAN
CycleGAN은 앞선 GAN들과 달리, Unpaired한 이미지들로 변환할 수 있는 모델이다. 예를 들면, 사진(X)과 그림(Y)들간의 데이터셋을 준비한다. 여기서 Unpaired하다는 의미는 사진을 그림으로, 그림을 사진으로 변환한 이미지를 준비하지 않았다면, 절대로 X에는 Y가, Y에는 X가 존재하지 않을거라는 의미이다. 물론 여기서 X는 항상 사진, Y는 항상 그림일 필요는 없다. 아래 예시처럼 모네 그림을 모아둔 데이터와 사진을 모아둔 데이터를 준비하면 모네가 봤던 풍경을 사진으로, 사진을 모네풍의 그림으로 변환시킬 수 있다. (정말 신기하지 않은가? 모네가 봤던 풍경을 우리가 사진으로 볼 수 있고, 우리가 지금 보고 있는 풍경을 모네풍의 그림으로 그릴 수 있다!). 이렇게 Unpaired 데이터가 있다면 서로 다른 도메인을 자유롭게 전환할 수 있다.

그럼 이게 어떻게 가능한걸까? 조금 더 알아보자면, 기존의 GAN과 크게 다르지 않다. CycleGAN은 두 개의 GAN을 Cycle형태로 구성했다고 해서 CycleGAN이라고 한다. 한마디로 정리하면 CycleGAN은 서로가 서로의 Generator이자 Discriminator가 되는 것이다. 이를 이해하기 위해선 Loss function을 잘 구성해야 하는데, 이를 조금 더 살펴보자.
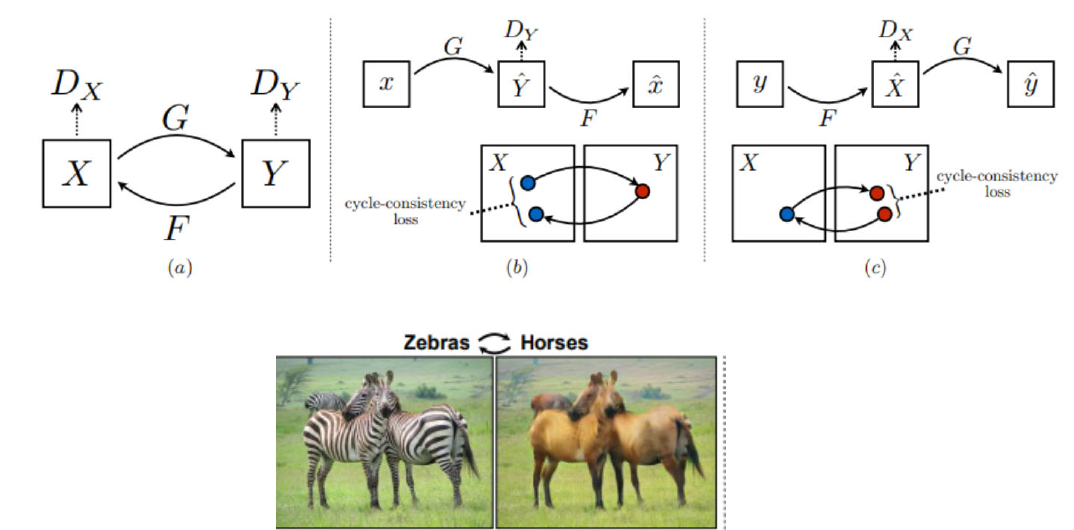

이게 가능한 이유는 Loss를 잘 구성했기 때문인데, CycleGAN은 기존의 Loss에 추가적으로 Cycle로 인한 Loss까지 추가하여 Cycle-consistency loss를 구성했다. 말(X)을 넣게 해서 얼룩말(Y)이 나오게 하고, 다시 그 얼룩말로 말이 나오게 해보자. 그럼 실제 말과 생성된 얼룩말 이미지를 통해서 다시 생성된 말과는 어느정도 차이가 생기는데, 이 때 차이를 cycle-consistency loss라고 명명했다. (사실 들어보면 이렇게 해야함이 타당하긴 하다.) 이 차이를 최소화해나가는 방향으로 학습해나가면 우리가 기대한 결과가 나올 것이다.

물론 이외에도 여러가지 GAN이 존재하지만, GAN과 관련된 글을 여기를 참고하여 더 확인해보자. 정말 쉽게 정리가 잘 되어있는 포스트이다.
글을 마무리하며
여기서 다루지 못한 수많은 생성모델이 있겠지만, 결국 어떠한 생성모델에서든 가장 중요한 것은 학습 데이터의 분포임을 잊지 말자.
참고자료
교수님의 강의록 외에도 이 글을 정리하는데 아래 블로그들의 도움을 많이 얻었다. 도움을 준 분들께 모두 감사드린다.
[머신러닝] 지도학습(Supervised), 비지도학습(Unsupervised), 강화학습(Reinforcement)
머신러닝을 통해 시스템이 어떻게 스스로 학습을 한다는 것일까? 결론부터 말하자면, 머신러닝은 어떤 데이터를 분류하거나 값을 예측하는 것이다. 분류하거나 값을 예측하는 것은 확률과 통계
marobiana.tistory.com
[AI] 머신러닝 지도학습(Supervised Learning) , 비지도학습(Unsupervised Learning) 차이점과 장단점
머신러닝 지도 학습과 비지도 학습 머신러닝에서는 크게 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning)으로 나눌 수 있습니다. 이 중 지도 학습과 비..
wendys.tistory.com
https://jayhey.github.io/semi-supervised%20learning/2017/12/08/semisupervised_generative_models/
생성 모델(Generative model)
이번에는 준지도학습(semi-supervised learning) 방법 중 하나인 생성 모델(generative model)에 대하여 알아보도록 하겠습니다. 클래스의 분포에 주목하는 방법 중 하나입니다.
jayhey.github.io
08. 오토인코더 (AutoEncoder)
이번 포스팅은 핸즈온 머신러닝 교재를 가지고 공부한 것을 정리한 포스팅입니다. 08. 오토인코더 - Autoencoder 저번 포스팅 07. 순환 신경망, RNN에서는 자연어, 음성신호, 주식과 같은 연속적인 데��
excelsior-cjh.tistory.com
AutoEncoder vs Variant AutoEncoder
AutoEncoder vs Variant AutoEncoder 조대협 (http://bcho.tistory.com) Abnormal AutoEncoder는 입력값을 기반으로 여기서 특징을 뽑아내고, 뽑아낸 특징으로 다시 원본을 재생하는 네트워크이다. 이미지 합성이..
bcho.tistory.com
https://dreamgonfly.github.io/2018/03/17/gan-explained.html
쉽게 씌어진 GAN
이 글은 마이크로소프트웨어 391호 인공지능의 체크포인트(THE CHECKPOINT OF AI)에 ‘쉽게 쓰이는 GAN’이라는 제목으로 기고된 글입니다. 블로그에는 이 글의 원제이자 윤동주 시인의 ‘쉽게 씌어진
dreamgonfly.github.io
https://www.youtube.com/watch?v=odpjk7_tGY0
'딥러닝(Deep Learning)' 카테고리의 다른 글
| [PyTorch] model.zero_grad() 와 optimizer.zero_grad() 차이 (0) | 2020.09.22 |
|---|---|
| Windows10에서의 CUDA 100% 설치 (0) | 2020.09.22 |
| 파이썬으로 퍼셉트론 구현하기 (0) | 2020.04.25 |